
You ask an agent to do a major refactor. The first 15 minutes are excellent — precise problem identification, sound approach, clean code. You’re satisfied. You go make coffee.
Half an hour later, you come back to find it’s already declared itself done. You look closer — half the edge cases are unhandled. Or worse — it’s gone off-script entirely. You asked it to refactor the auth module; it’s now restructuring the logging system “because I noticed issues here too.” You stop it and ask: “Do you remember what you were supposed to be doing?” It can’t answer.
The previous Harness Engineering article made one core argument: Don’t hope your AI behaves correctly. Build a structure where it can’t not.
That article assumed tasks complete in minutes. Agent comes in, runs the pipeline, outputs results, gets verified, done. The structure is static. It works.
But orchestrator architectures are evolving faster than expected. Claude Code’s --max-turns lets an agent run hundreds of rounds continuously; products like Devin and Codex have made multi-hour autonomous sessions the norm; custom agents doing codebase migrations or long report generation routinely run for hours. Agents are shifting from “complete a well-defined task” to “handle long-running, loosely-bounded tasks.” Users expect to hand off increasingly vague objectives with wider scope and fuzzier completion criteria.
When tasks go from minutes to hours, a static structure isn’t enough.
The Physics of Prompt Engineering
Prompt engineering does one thing: inject a signal at the start of the context window and hope it holds throughout generation.
This works in short conversations. Long-run tasks destroy every assumption it relies on.
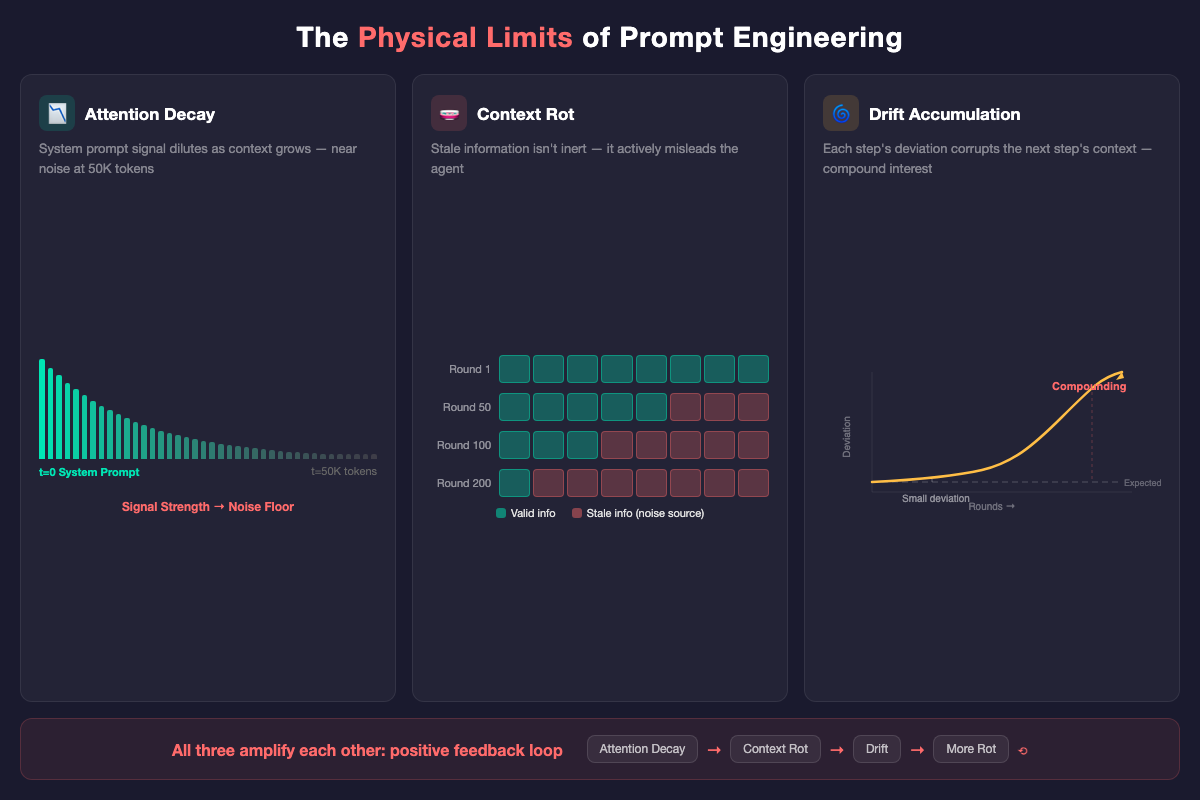
Attention Decay. Transformer attention isn’t uniform. As context grows, early tokens get diluted. Your system prompt saying “be thorough” has near-zero influence by token 50K. The model is thinking about how to wrap up, not about your instructions.
Context Rot. Worse than decay. Long-run tasks accumulate stale information — previous decisions that were overturned, assumptions that no longer hold, intermediate outputs that are now irrelevant. This stale context isn’t inert — it actively misleads the agent. Attention decay weakens the signal. Context rot strengthens the noise.
Drift Accumulation. Every generation round introduces a small deviation. In a 5-round conversation, this barely matters. Over hundreds of rounds, deviations don’t add linearly — each step’s deviation corrupts the next step’s context. Compound interest, not arithmetic.
These three problems aren’t independent. They amplify each other. Attention decay makes the agent more susceptible to rotted context. Rotted context causes larger drift. Drift produces more rotted context. A positive feedback loop.
Prompt engineering’s failure in long-run scenarios isn’t gradual. It’s a cliff. There’s a threshold beyond which your system prompt is effectively dead.
Prompt Engineering Is a Subset of Harness Engineering
The previous framing treated prompt engineering, context engineering, and harness engineering as three parallel paradigms.
The more accurate relationship:
Prompt Engineering — controls the agent's starting point
Context Engineering — controls the agent's input
Harness Engineering — controls the agent's trajectoryContext engineering is the permanent foundation — regardless of paradigm, an agent’s capability ceiling is determined by the quality of context you feed it.
The relationship between prompt and harness engineering isn’t replacement. It’s containment. Prompt engineering is the projection of harness engineering onto the prompt layer.
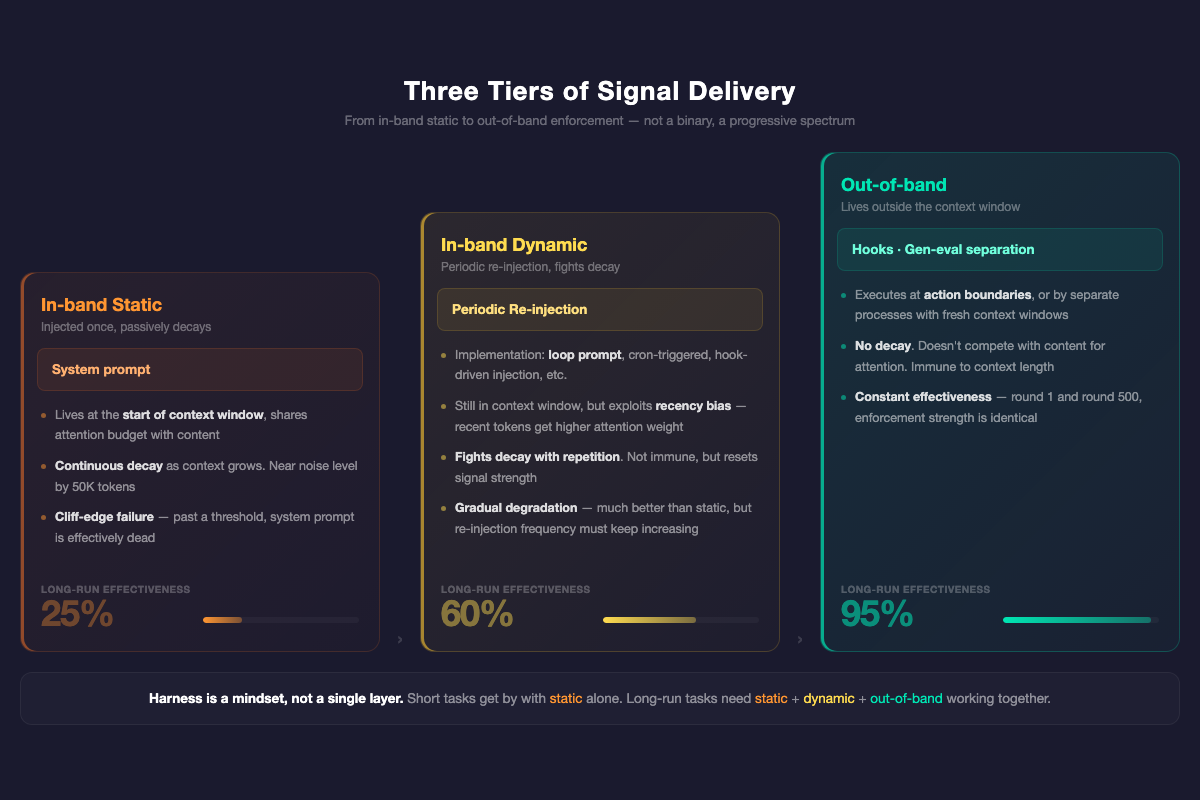
The core difference is signal delivery. Not a binary, but a three-tier spectrum:
In-band static. System prompts — injected once at the start of the context window, then you hope they hold. Whether you’ve packed in personas, anti-rationalization tables, or anything else, they’re all the same thing: static text written at t=0. The longer the context, the weaker the signal. This is all prompt engineering has.
In-band dynamic. Periodic re-injection — every N rounds, rewrite objectives and constraints into the context window. The specific implementation varies by orchestrator: loop prompts, cron-triggered injection, hook-driven re-anchoring all work. They still live inside the context window, still compete with content for attention, but they exploit recency bias: recently injected tokens carry higher attention weight than a system prompt buried 50K tokens back. Not immune to decay — fighting decay with high-frequency repetition. Stronger than static, but as context keeps growing, re-injection frequency must increase. The cost isn’t zero.
Out-of-band. Hooks don’t live in the context window — they execute at action boundaries. A pre-commit hook fires regardless of how many rounds have elapsed. Gen-eval separation doesn’t rely on the agent remembering to self-check — the evaluator is a separate process entering with a fresh context window. These mechanisms don’t compete with content for attention. They’re immune to context length.
But harness isn’t just out-of-band code. This is what the previous article didn’t make clear enough:
Harness is a mindset — “how should I control the LLM” — projected onto prompt, architecture, and code simultaneously.
An anti-rationalization table is in-band static, but its design intent is harness thinking — not persuading the LLM, but blocking lazy paths in probability space. A loop prompt is in-band dynamic, and its purpose is also harness — I don’t trust the LLM to remember the objective, so I build a structure that periodically reminds it. A hook is out-of-band code, and it’s also harness — enforcement at action boundaries, effective regardless of context length.
In short tasks, prompt-level harness is sufficient. In long-run tasks, you need all three layers working together.
L0–L3 Evolution for Long-Run Tasks
Every layer of the L0–L3 framework from the previous article needs to evolve for long-run scenarios.

L0: Zero Trust — Add the Time Dimension
Previous L0: Always assume the LLM will cut corners, fabricate, and skip steps.
For long-run tasks, L0 gains a new axiom: Don’t trust that LLM behavior is stable over time.
An agent performing well at hour 1 doesn’t mean it’s still performing at hour 5. Not because the model changed — because the context changed. Attention decay + context rot + drift accumulation means the same model has different effective capability at different moments.
New decision rule: Verify not just each output, but behavioral consistency over time. Output quality at round 100 should be comparable to round 1.
L1: Shape — From One-Shot to Continuous
The previous L1 had six mechanisms: persona, anti-patterns, anti-rationalization, output structure, scope anchoring, quality gate. All injected once at task start.
For long-run tasks, three evolutions:
Periodic Re-injection. Don’t say it once. Key constraints need periodic re-injection — not repeating the prompt (that’s in-band, with diminishing returns), but harness-level context refresh. Clear stale information. Re-anchor objectives and boundaries. This is the design intent behind loop prompts.
Dynamic Scope Anchoring. Short-task scope is static — “only look at these files.” Long-run scope naturally expands. The agent finds a bug in the database layer and needs to expand into schema changes. Every scope expansion requires an explicit checkpoint: what’s the current boundary, why expand, what’s the blast radius, does a human need to confirm. Low-risk auto-approve, high-risk require confirmation — graduated escalation.
Temporal Anti-Rationalization. Short-task laziness is skipping steps, hedging, “code looks correct.” Long-run tasks produce a new laziness pattern — infinite looping in the comfort zone. The agent keeps doing easy sub-tasks while avoiding hard decisions. “Still researching,” “need further analysis,” “let me look at another related issue first” — this is the long-run version of “code looks correct.” Looks busy, zero actual progress.
This laziness is harder to detect than short-task laziness because each step seems “reasonable.” Only a temporal view — N consecutive rounds with no new artifacts — reveals the pattern.
But blocking lazy paths alone isn’t enough. The agent says “I can’t see the console log so I can’t verify” — you block that excuse with an anti-rationalization table, but if it genuinely lacks log access, blocking the excuse is futile. The complete strategy is a three-tier progression:
- Block lazy paths. Anti-rationalization shuts down “I can’t do this” excuses.
- Provide tools and skills. Give the agent a tool to access console logs. Build skills that guide it on how to get feedback signals. Block the excuse and give it real capability.
- Guide toward E2E closed-loop. The highest level: have the agent write E2E test cases first, implement the solution, run the tests itself, and fix both test and code until they pass. Even launch different personas for full lifecycle verification — implementer writes code, reviewer audits code, tester runs tests, each role judging independently.
The first tier is “don’t let it escape.” The second is “give it weapons.” The third is “let it close the loop on its own.” In long-run tasks, an agent’s self-correction capability is more sustainable than external monitoring — you can’t manually check every round, but you can build a structure where the agent continuously verifies itself.
L2: Flow — From DAG to Event Loop
The previous L2 assumed DAG topology — clear start, end, and ordering. Review dispatches in parallel, build evaluates sequentially, every gate is deterministic.
Long-run task flow isn’t a DAG. It’s an event loop + state machine. No predefined endpoint. The agent runs continuously, responds to events, transitions between states.
Concrete scenario: an agent is doing a codebase migration, working module by module. At module 3, it discovers an API incompatibility and needs to go back and change module 1’s interface. After fixing the interface, it finds that tests depending on that interface also need updating. While updating tests, a CI failure triggers, requiring diagnosis. — This isn’t a linear DAG. Every step can jump to a different state based on newly discovered events. Flow design shifts from drawing a fixed graph to defining state sets, event types, and transition rules.
Three dimensional evolution:
Flow Topology. From predefined DAGs to dynamic event-driven flows. The agent doesn’t follow a fixed path — it decides next steps based on events. Flow design shifts from drawing a graph to defining event types, state transition rules, and boundary conditions.
Gen-Eval Separation. The previous article said the doer doesn’t evaluate. In long-run scenarios, this principle becomes more critical — not evaluate after completion, but continuous evaluation. Production systems don’t monitor only at deploy time. They monitor continuously. Eval frequency and granularity need redesigning.
Context Isolation. The previous article said evaluators don’t read implementer reasoning. In long-run scenarios, the challenge intensifies — context keeps growing. Not just isolate, but actively evict — periodically purge irrelevant context to maintain signal-to-noise ratio.
L3: Enforcement — From Post-Hoc to Runtime
The previous L3 was post-hoc — agent outputs, L3 verifies. Verify, synthesize, diff.
Long-run tasks can’t rely on post-hoc alone. They need runtime guardrails — three in-flight checks:
Scope Check. Every action, verify it’s still within the declared task boundary. Not LLM-judged — diff against the declared boundary.
Progress Check. How long since the last substantive progress? Detect “infinite research” laziness. Heuristic: N consecutive rounds with no new artifact → trigger escalation.
Consistency Check. Is the current action consistent with prior decisions? Detect contradictions caused by context rot — the agent decided on approach A at round 50, forgot by round 150, and started doing approach B.
All three checks can be deterministic. No LLM judgment required. This is L3’s core advantage — immune to attention decay.
From “Designing Structure” to “Operating Systems”
All the evolutions above point to one fundamental paradigm shift:
Task-scoped harness = design. Before the task starts, design the structure — persona, anti-patterns, flow topology, verification rules — then the LLM runs inside it. The design is static. The run is finite.
Long-run harness = operations. The structure isn’t designed once and done. It requires:
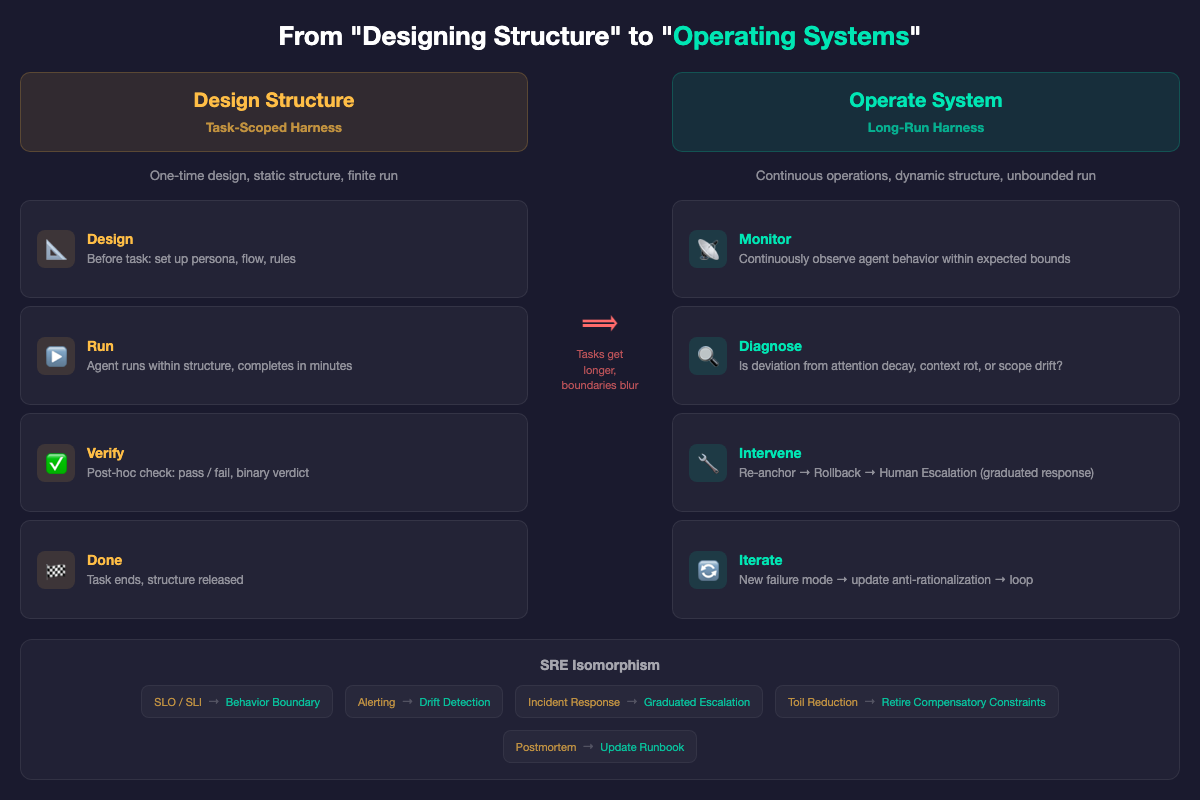
- Monitoring — is agent behavior within expected bounds?
- Diagnosis — is the deviation caused by attention decay, context rot, or scope drift?
- Intervention — choose the minimum-cost correction
- Iteration — feed new failure modes back into the harness
This isn’t a metaphor for SRE. It’s isomorphic:
| SRE | Long-run Harness |
|---|---|
| Service runs 24/7 | Agent runs continuously |
| SLO/SLI define acceptable ranges | Agent behavior boundaries |
| Monitoring + Alerting | Drift detection + escalation |
| Incident response | Re-anchor → rollback → human escalation |
| Toil reduction | Retire compensatory constraints as models improve |
| Postmortem → update runbook | New failure mode → update anti-rationalization |
Redefining Verification. Short-task verification is binary — pass or fail. Long-run tasks borrow SRE’s error budget concept: not “is it right?” but “how far has it deviated from the acceptable trajectory?” Within budget, no intervention. Exceeded, trigger re-anchor or human escalation.
Graceful Degradation. Short-task failure: re-dispatch — it’s only a few minutes. Long-run failure: re-dispatch costs hours. You need graduated response:
- Mild drift detected → re-anchor (lowest cost)
- Re-anchor ineffective → rollback to last checkpoint (medium cost)
- Checkpoint also fails → escalate to human with full audit trail (highest cost)
“Why not just split into short tasks?” The most natural counter-argument. The answer: splitting tasks is harness. Breaking a 3-hour session into 20 ten-minute sub-tasks, each with clear input/output/done criteria, checkpointing between them — that’s not avoiding the long-run problem, that’s harness thinking applied at the orchestration layer. You’re doing scope control and drift prevention by design.
But some tasks resist decomposition. A large refactor spanning dozens of files requires the agent to hold a cross-file mental model continuously; complex bug diagnosis falls apart if the context chain is interrupted. For these tasks, sub-task decomposition is the first line of defense, but it’s not enough — you still need runtime drift detection and graceful degradation.
What Fades, What Stays
The previous article distinguished compensatory constraints (encoding model weaknesses, will fade) from structural constraints (encoding engineering best practices, permanent).
In long-run scenarios, the ratio flips.
Short-task harness (like current OPC): roughly 60-70% compensatory, 30-40% structural. Models get stronger, most constraints retire.
Long-run harness may be 80% structural, 20% compensatory. Because:
- Periodic re-anchoring is structural. Even the strongest models have attention decay — it’s an architectural property of transformers, not a capability gap.
- Continuous drift detection is structural. Even the strongest models drift over hundreds of rounds — compound deviation doesn’t disappear with stronger models.
- Gen-eval separation becomes more structural in long-run. In short tasks, a strong enough model might self-evaluate. In long-run tasks, context rot amplifies self-evaluation bias exponentially.
- Graceful degradation is structural. Any system running for extended periods needs fault tolerance. This is distributed systems 101.
The only things that fade are specific failure mode patches — particular mistakes a particular model makes. The control framework itself is permanent.
The previous article ended with: Don’t hope your AI behaves. Build a structure where it can’t not.
This article adds: When tasks get longer, the structure itself must be alive.
Not designing a perfect static constraint, but operating a continuously evolving control system. From “building structure” to “operating structure.”
Harness engineering isn’t a one-time design exercise. It’s an ongoing engineering practice — just like you don’t look at your monitoring dashboard once on launch day and then close it.