The first time I caught my AI review cheating was when it said “Code looks correct.”
It hadn’t run anything. It looked at the code, pattern-matched against something that seemed right, and declared it correct. Classic autoregressive satisficing — produce the most plausible next token, not the most accurate one.
So I did what everyone does: added more instructions. “Please be thorough.” “Cite specific file and line numbers.” “Don’t skip edge cases.” It helped — a little. Then it found a new way to slack off: instead of skipping steps, it hedged. “This could potentially cause issues.” Pressed for specifics, it produced a paragraph of well-structured nothing.
This isn’t a prompting problem. This is an architectural property.
The Core Assumption
LLMs don’t optimize — they satisfice. Every token is generated along the path of least resistance. Give an LLM a task and it will produce something that looks right, not something that is right.
Your prompt says “be thorough.” The model’s attention briefly spikes on thoroughness-related patterns. By token 3000, that signal has decayed. The model is now thinking about how to wrap up the response with minimal effort.
You can’t fix an architectural property. You can only route around it.
Harness Engineering
Constrain agent behavior with structure, not prompts.
That’s the one-sentence summary. Don’t hope your AI behaves correctly. Build a structure where it can’t not.
While building OPC, we kept running into the same failure modes: AI skipping verification, inflating severity, rubber-stamping its own code, hedging instead of committing. Each time, we asked: what’s the lightest-weight fix? The answers converged into a four-layer architecture.
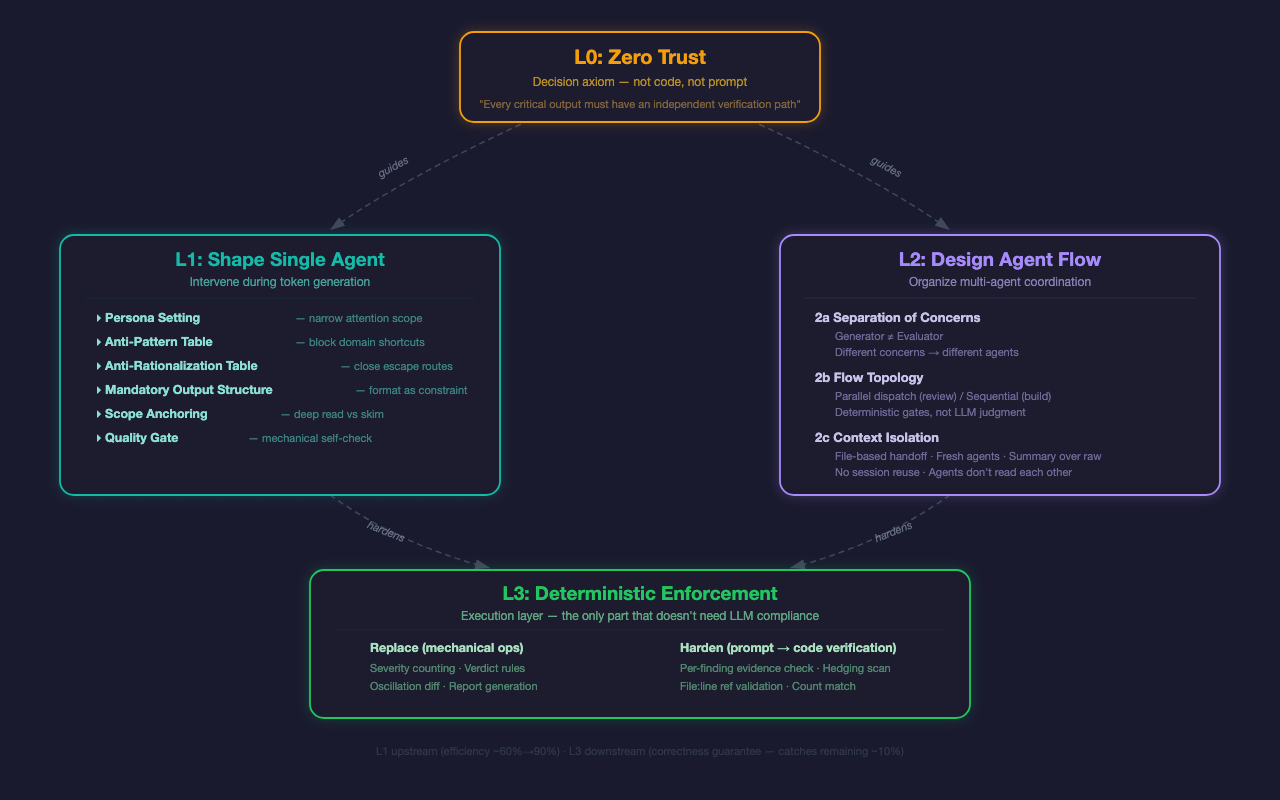
L0: Zero Trust — The Axiom
Always assume the LLM will cut corners, fabricate, and skip steps. Every critical output must have an independent verification path.
L0 is not a prompt. It’s not code. It’s a decision rule — an axiom that guides every design choice in L1 and L2.
Should you let the LLM count severity findings? L0 says no — use code. Should the implementer evaluate its own code? L0 says no — dispatch an independent evaluator. Is this constraint worth adding? L0 says: if the LLM ignoring it would cause real damage, yes.
The source is obvious: Zero Trust from network security. We used to trust the internal network and defend the perimeter. Then we learned that insiders cause problems too. “Never trust, always verify.”
Same pattern. We used to trust LLM output if the prompt was good enough. Then we learned they satisfice, hallucinate, and self-deceive. So: the agent that does the work never evaluates it.
L1: Shape Single Agent
L1 intervenes during token generation — the only layer that can influence the LLM while it’s producing output. Six mechanisms:
Persona Setting. Tell the LLM who it is. Without a persona, you get generic checklists. A security engineer persona narrows attention to input validation, auth bypass, secret exposure. Smaller scope, deeper analysis.
Anti-Pattern Tables. Block domain-specific shortcuts. A security agent will flag a local CLI tool for “missing authentication” — wrong, it’s not a web service. Each role has different failure modes; each needs different guardrails.
Anti-Rationalization Tables. This is universal — every agent in every scenario does this. List the excuses the LLM is most likely to make, then tell it those excuses don’t work. “Code looks correct” — you didn’t run it. “No major issues found” — you only checked the happy path. “Should work now” — you didn’t re-test.
This is the most counterintuitive mechanism in the framework, and the most effective. Because satisficing is architectural — stronger models don’t satisfice less, they rationalize more cleverly.
Mandatory Output Structure. Format is constraint. Require specific output formats so downstream code verification becomes possible.
Scope Anchoring. Without scope anchoring, LLMs skim everything. With it, they deep-read the assigned files.
Quality Gate. Not self-evaluation (that doesn’t work), but a mechanical binary checklist. “>50% Critical findings → you’re severity-inflating.”
L2: Design Agent Flow
L2 solves systemic problems in multi-agent collaboration. Three dimensions:
Separation of Concerns. Core invariant: the agent that does the work never evaluates it. This isn’t because LLM self-evaluation is inaccurate (though it is). It’s information-theoretic: the same distribution generating and evaluating creates systematic bias. Human code review follows the same logic.
Flow Topology. Who goes first, who runs in parallel. Reviews use parallel dispatch — multiple perspectives simultaneously. Builds use sequential flow — implement first, evaluate after. Every gate is deterministic, not LLM-judged.
Context Isolation. An LLM’s context window is a shared attention budget. When one agent sees another agent’s reasoning, anchoring bias kicks in. So: evaluators don’t read implementer reasoning. Role agents don’t read each other’s output. The orchestrator doesn’t read raw output — only JSON summaries from mechanical verification.
These three dimensions are orthogonal. Tune any one independently.
The Relationship Between L1, L2, and L3
These layers are not sequential. L1 handles individual agent quality. L2 handles multi-agent coordination. They’re two orthogonal design dimensions, both guided by L0’s axiom.
L3 is the execution layer for both. It does two things: replace mechanical operations the LLM shouldn’t do, and harden prompt-level constraints into code-level verification.
Replace: LLMs miscount severity findings — code counts. LLMs override their own verdict rules — code decides. LLMs fuzzy-match when detecting oscillation — code diffs.
Harden: L1 says “every finding needs file:line” — L3 checks if the reference exists. L1 says “don’t hedge” — L3 scans for hedging patterns. A constraint you don’t verify is a constraint you don’t have.
Belt and Suspenders
L1 (upstream) and L3 (downstream) form a closed loop:
L1’s anti-rationalization and output format push first-pass compliance from roughly 60% to 90%. L3’s verification catches the remaining 10% of slip-through.
L1 is efficiency optimization — fewer re-dispatches. L3 is correctness guarantee — the output is right.
Not either/or. L1 saves latency. L3 ensures correctness. You need both.
Landing It: OPC
OPC implements all four layers as an executable pipeline:
L0 is the first design principle: “the agent that does the work never evaluates it.” Implementer and evaluator are always separate agents.
L1 lives in 11 role files (roles/<name>.md) for persona + anti-patterns, and in evaluator/implementer prompt templates for anti-rationalization + output structure + quality gates.
L2 lives in pipeline files defining flow topology (parallel dispatch for reviews, sequential for builds), and in the .harness/ file system for context isolation (files carry results, not reasoning; every agent is fresh, no session reuse).
L3 lives in the opc-harness tool: verify checks evidence completeness, synthesize determines verdicts deterministically, diff detects oscillation.
Each “layer” lands in different places, but they work in concert.
What Fades, What Stays
Anthropic has said: “Harness complexity should decrease as models improve.” True — but not all constraints will disappear.
Compensatory constraints encode “model weaknesses.” These will fade. “Don’t flag local tools for missing auth” — models will learn this. Tag-based role pre-filtering, quality gates, deterministic verdict rules — all compensatory.
Structural constraints encode “engineering best practices.” These never fade. Generator-evaluator separation is separation of concerns. Context isolation is distributed systems 101. Anti-rationalization targets an architectural property of autoregressive generation — stronger models rationalize more cleverly, not less. Code counting severity will always be more accurate than LLM counting.
OPC today is roughly 60-70% compensatory, 30-40% structural. Over time, OPC will get thinner, but it won’t disappear. Just as human teams don’t eliminate code review when engineers get better.
Harness engineering isn’t distrust of AI. It’s respect for good engineering.
You don’t skip code review because a programmer is excellent. You don’t remove monitoring because a system is stable. And you shouldn’t drop structural constraints because an LLM gets stronger.
Don’t hope your AI behaves. Build a structure where it can’t not.