第一次发现 AI review 在偷懒,是在它说了一句 “Code looks correct” 之后。
它没跑过。它只是看了一眼,觉得长得像对的,就说对了。
你会觉得这是个 bug——prompt 写得不够好,约束不够多。于是你加一句 “please be thorough”,加一句 “don’t skip edge cases”,加一句 “cite specific file and line numbers”。有用吗?有一点。稳定吗?完全不。下次它换个方式偷懒:不跳步骤了,改成 hedge——“this could potentially cause issues”。你追问,它就给你一个四平八稳的废话。
这不是因为你的 prompt 不够好。这是 autoregressive architecture 的固有属性。
LLM 的默认行为
LLM 生成每个 token 时,走的是阻力最小的路径。给它一个 task,它会产出一个”看起来对”的结果——不是最好的,只是够用的。学术上这叫 satisfice(满足即止),不是 optimize(追求最优)。
你在 prompt 里写 “be thorough”,它的 attention 确实会短暂聚焦到 thoroughness 相关的 pattern。但随着 context 变长,这个信号会衰减。到第 3000 个 token 的时候,它早忘了你说过要 thorough——它在想怎么用最少的 token 把这段收尾。
这不是 bug。你没法 fix 一个架构特性。
你只能绕过它。
Harness Engineering
用结构约束 agent 行为,而不是用 prompt 期望 agent 行为。
这就是 harness engineering 的核心:不期望 AI 行为正确,构造一个结构,让它想不正确都难。
在 OPC 的开发过程中,我们逐渐沉淀出一个四层架构。不是发明的——是被 failure mode 逼出来的。每次 AI 偷懒、编造、跳步骤,我们都问同一个问题:最轻量的对策是什么?答案逐渐收敛成了四个层次。
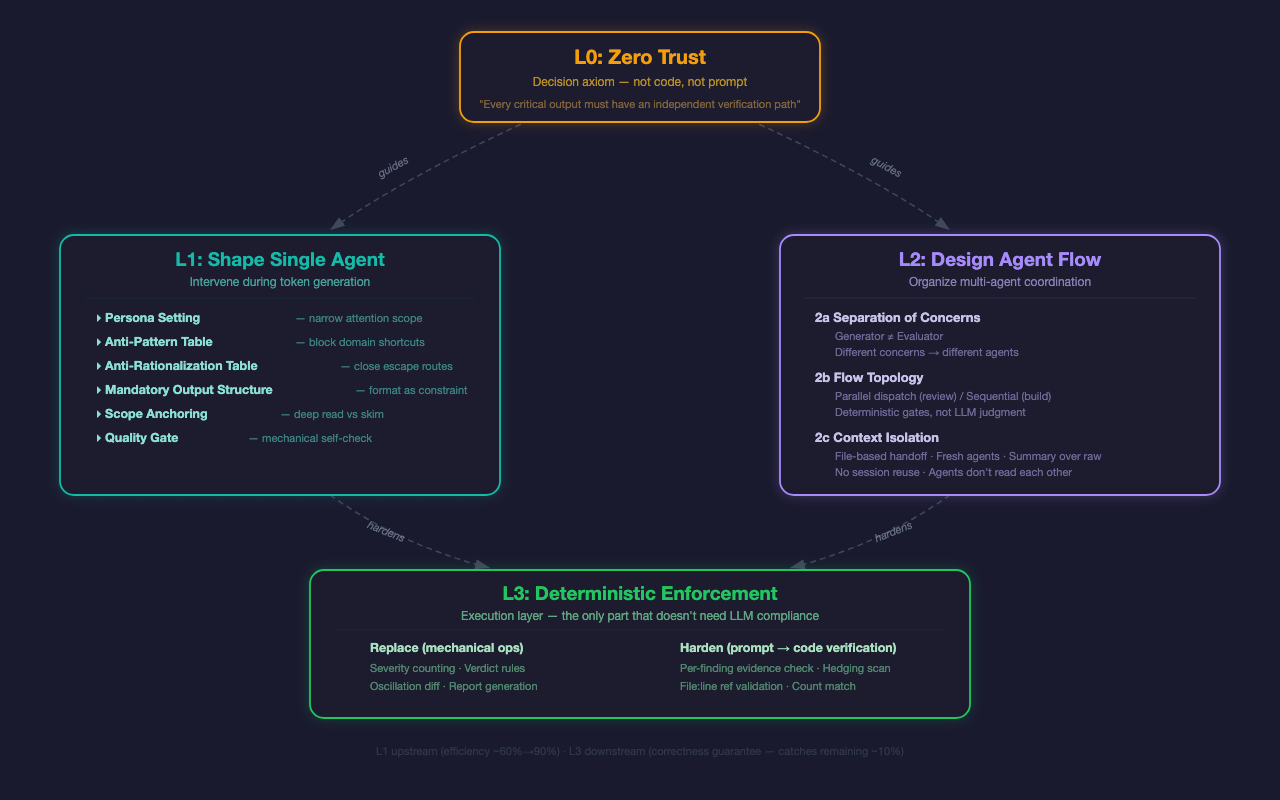
L0: Zero Trust — 公理
永远假设 LLM 会偷懒、会编造、会跳步骤。每个关键输出都必须有独立验证路径。
L0 不是 prompt,不是代码,是 decision rule。它指导你在 L1 和 L2 中做每一个设计决策。
犹豫要不要让 LLM 自己数 severity count?L0 说不,用代码。犹豫要不要让 implementer 自评代码?L0 说不,dispatch 独立 evaluator。犹豫这个 constraint 值不值得加?L0 说:如果 LLM 忽略它后果严重,加。
这个原则的来源很清楚:网络安全的 Zero Trust 架构。以前我们信任内网,防御边界。后来发现内部人员也会出问题。于是 “never trust, always verify”。
对 AI agent 也一样。以前给好 prompt,信任输出。后来发现 AI 会偷懒、幻觉、overconfident。于是:做事的人不评价。
L1: Shape Single Agent — 塑造单兵
L1 在 token generation 阶段介入——这是唯一能在生成过程中影响 LLM 的层。六个机制,从身份到自检:
Persona Setting — 告诉 LLM “你是谁”。没有 persona 的 agent 输出 generic checklist;一个安全工程师 persona 会聚焦到 input validation、auth bypass、secret exposure。缩小 attention scope。
Anti-Pattern Table — 堵住特定领域最可能走的偷懒路径。安全 agent 会对本地 CLI 工具报”缺少 auth”——这是错的,因为它不是 web 服务。每个角色的偷懒方式不同,anti-pattern 也不同。
Anti-Rationalization Table — 这是通用的,所有 agent 在所有场景下都会犯的偷懒。把 LLM 最可能说的借口列出来,然后告诉它这些借口不成立。“Code looks correct”——你没跑过。“No major issues found”——你只看了 happy path。“Should work now”——你没 re-test。
这不是客气的 “please be careful”。这是把所有退路堵死,让它只剩一条路可走:做真正的工作。
Anti-rationalization 是整个框架里最反直觉但最有效的机制。因为 satisficing 是架构层面的——模型变强不会让它消失,只会让它更聪明地 rationalize。
Mandatory Output Structure — 格式即约束。要求特定的输出格式,让下游的代码验证成为可能。
Scope Anchoring — 不锚定范围,LLM 会 skim everything;锚定了,deep-read the scope。
Quality Gate — 不是 self-evaluation(那不 work),是简单的 binary checklist。“>50% Critical → 你在 severity-inflating” 这种。
L2: Design Agent Flow — 设计阵型
L2 解决的不是单兵质量,是多 agent 协作时的系统性问题。三个维度:
Separation of Concerns — 核心不变量:做事的人不评价。 不是因为 LLM 自评不好用(虽然确实不好用),是信息论层面的原则:同一个 distribution 生成和评价,bias 是系统性的。人类 code review 也是这个逻辑。
Flow Topology — 谁先谁后,谁和谁并行。Review 用 parallel dispatch(多角度同时看),Build 用 sequential(先做再评)。每个 gate 是确定性的,不是 LLM 判断。
Context Isolation — LLM 的 context window 是共享的 attention budget。一个 agent 看到另一个 agent 的推理过程,会被 anchor bias 影响。所以:evaluator 不读 implementer 的推理,role agents 不读彼此输出,orchestrator 不读 raw output——只读机械验证的 JSON summary。
这三个维度是正交的。你可以单独调整任何一个。
L1 和 L2 的关系
L1 和 L2 不是层层递进的。 L1 管单兵素质,L2 管组织阵型——它们是两个正交的设计维度。
L1 解决的问题是:一个 agent,如何让它的输出质量尽可能高。L2 解决的是:多个 agent,如何组织它们让系统性问题不出现。
一个没有 L1 的系统,agent 输出垃圾,L2 的阵型再好也没用。一个没有 L2 的系统,单兵再强,自评自己的代码还是有 bias。
L3: Deterministic Enforcement — 执行层
L3 不是第三个”层”。它是 L1 和 L2 的执行层。
L3 做两件事:替代(LLM 不该做的机械操作)和硬化(把 prompt-level 约束变成 code-level 验证)。
替代:LLM 数 severity count 会数错——代码来数。LLM 判定 verdict 会 override 自己的规则——代码来判。LLM 检测 oscillation 用 fuzzy match 不可靠——代码来 diff。
硬化:L1 说”每个 finding 要有 file:line”,L3 验证 findings_without_refs 是否为空。L1 说”不要 hedge”,L3 扫描 hedging pattern。L1 说了的,L3 必须能验证。说了不查等于没说。
Belt and Suspenders
L1(upstream)和 L3(downstream)形成闭环:
L1 的 anti-rationalization 和 output format,把 first-pass compliance 从大约 60% 提到 90%。L3 的 verify 和 synthesize,兜住剩下 10% 的 slip-through。
L1 是效率优化——减少 re-dispatch 的次数。L3 是正确性保证——确保最终输出是对的。
不是二选一。L1 省 latency,L3 保 correctness。两个都需要。
OPC 落地
OPC 把这四层落地为一套可执行的 pipeline:
L0 体现在第一行设计原则:“做事的人不评价。” Implementer 和 evaluator 永远不是同一个 agent。
L1 通过 11 个 role 文件(roles/<name>.md)实现 persona + anti-pattern,通过 evaluator 和 implementer 的 prompt 模板实现 anti-rationalization + output structure + quality gate。
L2 通过 pipeline 文件定义 flow topology(review 并行 dispatch,build 串行 evaluate),通过 .harness/ 文件系统实现 context isolation(文件传结果,不传推理;每次 fresh agent,不复用 session)。
L3 通过 opc-harness 工具实现机械操作:verify 检查 evidence,synthesize 判定 verdict,diff 检测 oscillation。
每个”层”的落地位置都不同,但它们协同工作。
什么会消失,什么会留下
Anthropic 说过:“Harness complexity should decrease as models improve.” 但不是所有 constraint 都会消失。
补偿性 constraint — 编码”模型的弱点”。模型变强就淘汰。比如:“不要对本地工具报缺 auth” 这种 anti-pattern,模型迟早会有这个常识。Tag-based role pre-filter、quality gate、deterministic verdict rules——这些都属于补偿性。
结构性 constraint — 编码”工程最佳实践”。永远不淘汰。Gen-eval separation 是 separation of concerns,context isolation 是分布式系统基本功,anti-rationalization 对抗的是 autoregressive 架构的固有属性——更强的模型会更聪明地 rationalize,不是更少。用代码数 severity 永远比让 LLM 数更准。
OPC 当前大约 60-70% 是补偿性,30-40% 是结构性。长期来看,OPC 会越来越瘦,但不会消失。 就像人类团队不会因为成员变强而取消 code review 制度。
Harness engineering 不是对 AI 不信任。是对好工程的尊重。
你不会因为一个程序员很优秀就不做 code review。你不会因为一个系统很稳定就不加 monitoring。同样,你不应该因为 LLM 变强就去掉结构性约束。
别期望 AI 行为正确。构造一个结构,让它想不正确都难。