“The ceiling of an AI agent is its tool interface.”
这一章讲一件事:你给 AI agent 的接口设计,决定了它能做什么、不能做什么、以及在哪里会崩溃。
不是 prompt engineering。不是 model selection。是协议层——你给 agent 的工具接口怎么设计。
在我最近一个密集项目里得到的最深刻教训就是这个:当 agent 失败时,80% 的原因不是模型不行,是我给它的工具不行。修好工具,同一个模型立刻能完成之前做不到的事情。
前言提到的 harness,第一层就是协议层。这一章从一个反直觉的决定开始——我为什么不依赖 vector database 作为 agent memory 的主架构。
1.1 从 Vector Database 到 Zettelkasten
2024-2025 年,AI 圈谈 memory 必谈 RAG。这套架构你大概已经见过:文档切片,embedding,存入 vector database,query 时做 similarity search,top-K 塞进 context。
这套方案我试过。不止试过,我在三个项目里用过 Pinecone、Weaviate、Chroma。
让我讲一个具体的失败。在第二个项目里,我让 agent 用 RAG 查找”MCP tool description 的设计原则”。vector search 返回了五条结果——其中三条是关于”REST API documentation best practices”的内容。因为在 embedding 空间里,“tool description”和”API documentation”的距离很近。
我花了两个小时试图修复:换 chunk size,调 overlap ratio,尝试不同的 embedding model。毫无进展。embedding 向量是上千维的浮点数,你没法看着它说”啊,这里第 834 维的值偏高了所以匹配错了”。你能做的就是改参数,然后祈祷。
这不是工程,这是炼金术。
结论:对于 agent memory 这个场景,vector database 是错误的主架构。
为什么?三个原因,以及一个更好的方案。
第一,embedding 搜索不可 debug
相比之下,显式链接是人类可读的、可 debug 的、可修改的。卡片 A 链接到卡片 B,因为创建链接时认为它们相关。agent 沿着链接走的时候,每一步都有迹可循。
第二,one-shot retrieval 不适合复杂问题
RAG 的标准流程是:query → retrieve → generate。一次检索,一次生成。
但真实的工程问题很少是一次检索能解决的。比如 agent 遇到一个 MCP tool timeout 的 bug,它需要:先找已知问题 → 发现跟 tool description 设计有关 → 找到设计原则 → 定位到 self-containment 约束 → 最终理解 timeout 根因。
这是一个 5 步的探索过程。你可以说”那我做 multi-hop RAG”——可以,但这时候你本质上在用 vector similarity 模拟 graph traversal,为什么不直接用 graph?
第三,token 只会越来越便宜
token 价格每 12-18 个月降一个数量级,这个趋势已经持续两年且没有放缓迹象。当 token 便宜到一定程度,直接让 LLM 读原文、做判断、沿链接探索,在经济上完全可行。
Zettelkasten:一个更好的方案
在这里先简单介绍一下 Zettelkasten。这个方法源自德国社会学家 Niklas Luhmann——他用一个装满索引卡片的柜子写了 50 多本书和 600 多篇学术文章。核心思想很简单:每张卡片记录一个原子化的想法,卡片之间通过显式链接形成知识网络。没有层级目录,没有分类体系,只有卡片和链接。知识的结构从链接关系中涌现。
Zettelkasten 有一个反直觉的核心原则:连接比存储更重要。 传统笔记系统帮你”找到你以为在搜索的东西”——你搜一个关键词,找到对应的笔记。Zettelkasten 做的是另一件事:呈现你已经忘记的想法。 你沿着链接走,走到第三步发现一张三个月前写的卡片,突然意识到当时那个想法和眼前的问题有关。这种 serendipity 不是搜索能给你的。
还有一条铁律:绝对不要 Copy Paste。 每张卡片必须用自己的语言重新表述。这不是矫情——存储时花的力气越大,提取时越容易。原文复制过来的东西,三天后你自己都读不懂当时为什么觉得重要。用自己的话翻译一遍,就是在强制自己消化。对 agent 来说也一样:memex_retro 要求 agent 用自己的语言总结 learning,而不是把 log 原文贴进去。
把 Zettelkasten 应用到 agent memory,核心在三个替换:
LLM 替代 Embedding。 不用 embedding model 把文本映射到向量空间,直接让 LLM 读卡片原文,理解内容,决定下一步去哪里。LLM 的语义理解远超 embedding——它能理解”这段讲的是原因,那段讲的是结果”,而且能结合当前任务的 context 判断相关性。同一张卡片在不同的任务语境下”相关程度”不同,embedding 做不到这种 context-sensitive 的判断。
显式链接替代 Vector Similarity。 Vector similarity 只有一个维度:像不像。显式链接的语义更丰富——因果关系、演化关系(“这个设计后来被替代了”)、依赖关系、甚至反对关系。链接的含义由上下文决定,而 LLM 最擅长理解上下文。并且链接是通过 [[wikilink]] 语法直接写在卡片正文里的——agent 在写卡片时自然地嵌入链接,比调用独立的”创建链接”命令更优雅。
Iterative Exploration 替代 One-shot Retrieval。 agent 在解决问题时往往不知道自己要找什么。它只有一个模糊的方向,然后需要在知识网络中探索。agent 读一张卡片,看到 [[wikilink]],调用 links 查看链接目标,用 read 读取下一张,再看链接,继续决策——每一步都有 LLM 的判断参与。不是机械的 similarity ranking,是有上下文的、有推理的探索。
一个重要的补充: memex 后来确实加入了 embedding 作为辅助搜索手段(支持 OpenAI、本地 GGUF 模型、Ollama 三种 provider,以及 0.7 * semantic + 0.3 * keyword 的 hybrid scoring)。但这是可选增强,不是主架构。主架构始终是 wikilinks + keyword search + 迭代探索。embedding 在你需要模糊语义搜索时有价值,但知识的结构、agent 的导航路径、debug 的可追溯性——这些都建立在显式链接上。
这恰好说明了好的架构支持渐进增强:先跑通核心路径,再按需叠加能力。
公平地说,vector database 在某些场景下确实更优——比如海量非结构化文档的粗筛,或者用户不维护任何知识结构的 “dump everything” 模式。我的结论限定在 agent memory 这个场景:agent 需要的是可 debug 的、可迭代探索的、跨 session 积累的结构化知识,不是一个黑箱搜索引擎。
为什么 Memory 被系统性低估
Agent memory 是 AI 领域目前被系统性低估的方向之一。绝大多数 agent 的”记忆”还停留在 conversation history 层面——session 结束,记忆消失。这就像一个每天早上失忆的员工:你每次都要从头教,永远无法积累团队知识。
从 conversation history 到结构化长期记忆,这不是渐进式改善,是跃迁。conversation history 是线性的、短期的、绑定在单个 session 里的。Zettelkasten 式的 memory 是网状的、持久的、跨 session 积累的。前者是工作记忆,后者是外脑。一个只有工作记忆的 agent 能干活,但它永远不会”变聪明”——它不会从经验中学习,不会在第 50 次 debug 时比第 1 次更快。
Zettelkasten 本质上就是 agent memory 的等价替换。Luhmann 用卡片盒构建了一个外部大脑,让他能在几十年的时间跨度上积累和连接知识。agent 的 memex 做的是完全一样的事情——只是时间尺度从几十年压缩到了几周,卡片数量从几万压缩到几百。结构不变,原理不变。
1.2 CLI 作为协议层的设计哲学
有了 memory 系统的设计方向,下一个问题是:怎么让 agent 使用它?
最直觉的答案可能是:写一个 Python SDK,提供 API,agent 调用就行了。
我的选择不一样。我选了 CLI。
不是因为怀旧,不是因为”Unix 哲学”的信仰——是因为这是我在实战中踩坑之后得出的最优解。
CLI 是纯数据层,Skill 是智能层
看这个分层:
┌─────────────────────────────┐
│ Skill Layer (智能层) │ → 包含 LLM 调用、判断逻辑、工作流编排
├─────────────────────────────┤
│ CLI Layer (协议层) │ → 纯数据操作、无 LLM 依赖、确定性行为
├─────────────────────────────┤
│ Storage Layer (存储层) │ → Plain text、Markdown、Git
└─────────────────────────────┘CLI 层做的事情:
# 写入卡片(通过 stdin 接收完整的 frontmatter + body)
echo "---
title: MCP Tool Timeout Fix
created: 2026-03-15
source: claude
---
Root cause: tool internally called a slow external API.
Fix: pass state as parameter instead.
See also: [[mcp-tool-self-containment]]" | memex write mcp-tool-timeout-fix
# 读取卡片
memex read mcp-tool-timeout-fix
# 搜索(支持关键词搜索和 manifest filter)
memex search "timeout"
memex search --tag "mcp" --category "bugfix"
# 查看链接关系
memex links mcp-tool-timeout-fix
# 查看反向链接(谁链接到了这张卡片)
memex backlinks mcp-tool-self-containment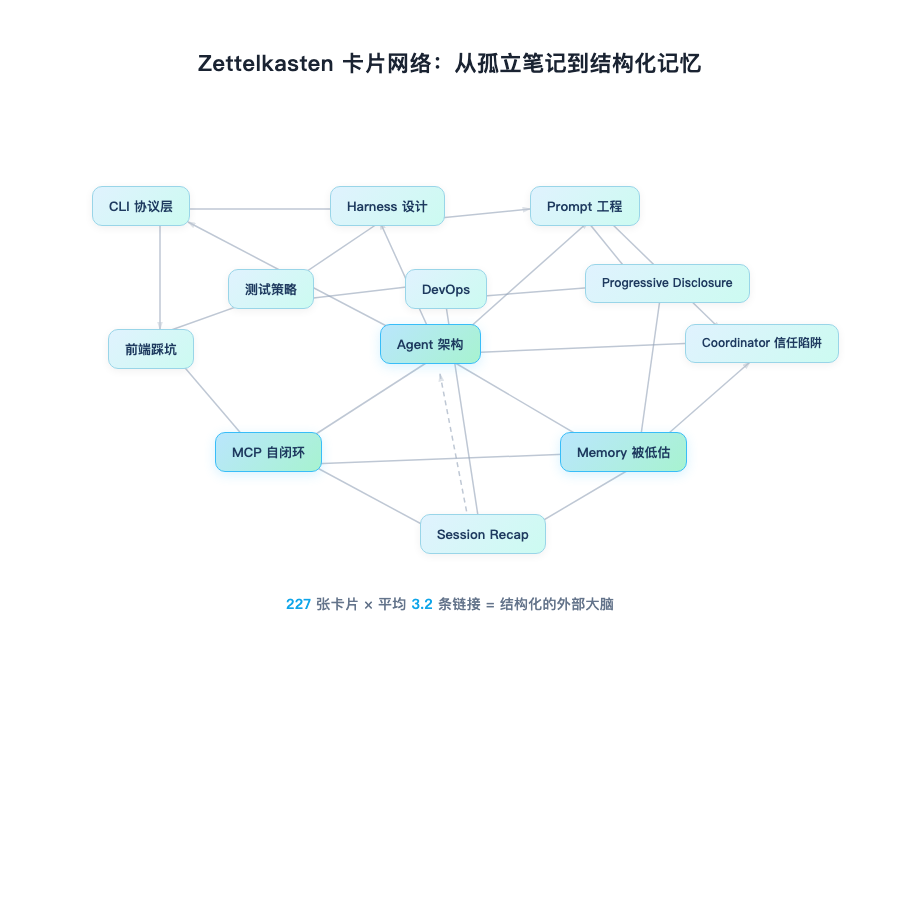
注意这些命令的特点:
- 无 LLM 依赖。每个命令都是确定性的。输入相同的参数,永远得到相同的结果。
- 纯数据操作。写入、读取、搜索、查链接——全是数据操作。没有”帮我总结”、“帮我判断”这种需要智能的功能。
- 每个命令做一件事,复杂功能靠 agent 自己组合调用链——agent 就是最好的 pipe operator。
智能层(Skill)负责的是:读取任务描述 → 判断需要哪些 memory → 调用 CLI 检索 → 读取结果 → 判断是否足够 → 如果不够,沿链接继续探索 → 综合所有信息 → 开始执行任务。这里的每个”判断”和”综合”都由 LLM 完成,每个”读取”和”检索”都由 CLI 完成。
为什么不做成 API/SDK?
CLI 的独特优势是人机两栖。 人可以在终端里手动 debug、手动维护 memory、手动验证 agent 的操作结果。memex read some-card 回车就能看到内容,出了问题肉眼就能排查。API/SDK 做不到这种零成本的人工介入。
同时,CLI 天然可测试——每个命令都可以在终端里手动跑一遍确认。天然可组合——管道、重定向、脚本,Unix 30 年的工具链直接可用。而且任何 agent 框架——Claude Code、Cursor、Windsurf——都能调用 CLI 命令,不挑语言,不挑环境。
Memory 独立于任何 Agent 环境
这一点至关重要。memory 系统是一个独立的 CLI 工具。它不知道自己被谁调用——是 Claude Code,还是 Cursor,还是人在终端里手打命令。它不关心。
这意味着:你可以换 agent 框架,memory 不受影响。你可以同时用多个 agent 框架访问同一个 memory。你可以在 agent 不在场的时候手动维护 memory。备份就是 memex sync push,恢复就是 memex sync pull——实际上 MCP server 在 recall 前会自动 fetch,retro 后会自动 push,连手动 sync 都省了。
这种解耦看起来理所当然,但我见过太多人把 memory 绑死在特定 agent 框架里。一旦框架升级或者换了产品,所有的 memory 都丢了。
Knowledge 是你最有价值的资产。不要把它锁在任何一个工具里。
1.3 三层分发模型:Tool Protocol → Instruction → Workflow
CLI 解决了”agent 怎么访问 memory”的问题。但 agent 能做的不只是访问 memory——它需要调用各种工具、遵循各种规则、执行各种工作流。这些能力怎么”分发”给 agent?
在实践中我发现了一个三层模型。不是设计出来的,是踩了足够多的坑之后从混乱中提炼出来的结构。
第一层:Tool Protocol(MCP)
MCP(Model Context Protocol)是 Anthropic 发起的 tool protocol,2025 年被主要 AI 编程工具广泛采用(Cursor、Windsurf、Claude Code 等)。它定义了 agent 可以调用哪些工具、每个工具接受什么参数、返回什么结果。
Tool Description 是运行时指令,不是文档
很多人写 tool description 的时候,像在写 API 文档:“Read a card by slug.” 简洁、准确、没用。
agent 看到这种 description,只知道工具能读卡片,不知道什么时候用、怎么用好、用错了会怎样。
看看 memex 的 memex_recall 的真实 description:
“IMPORTANT: You MUST call this at the START of every new task or conversation, BEFORE doing any work. This retrieves your persistent memory — knowledge cards from previous sessions with [[bidirectional links]]. Returns the keyword index (if exists) or card list. Optionally search by query. Without calling this first, you will miss context from prior sessions and repeat past mistakes.”
这不是文档,是运行时指令。它包含了:
- 使用时机:“at the START of every new task, BEFORE doing any work”
- 功能描述:“retrieves your persistent memory — knowledge cards”
- 使用策略:“Returns the keyword index (if exists) or card list”
- 后果警告:“you will miss context and repeat past mistakes”
本质上是把 instruction embed 到 tool interface 里。agent 不需要额外的文档来学习——tool schema 本身就是教程。
MCP Tool 必须自闭环
一个 MCP tool 被调用时,应该能仅凭自己的输入参数完成任务,不依赖外部状态。
反例:"Read the currently selected card." ——“currently selected”意味着存在外部状态,如果另一个 session 改了选中状态,行为不可预测。
正例:
{
"name": "memex_read",
"inputSchema": {
"properties": {
"slug": { "type": "string", "description": "Card slug (e.g. 'my-card-name')" }
},
"required": ["slug"]
}
}所有必要信息都在参数里。没有隐式依赖。确定性。可测试。
我曾经有一个 tool 依赖了”上一次操作的结果”——在单 session 里工作正常,多 session 并行时直接崩溃。debug 花了四个小时,修复只花了十分钟——把隐式状态改成显式参数。
高级操作:格式是工程问题,不要交给语言模型
场景是这样的:我让 agent 创建一张 Zettelkasten 卡片。最初的设计是给它一个低级的 write_file tool,让它自己按照 Zettelkasten 的格式拼 Markdown——YAML frontmatter 的字段、日期格式、wikilink 语法。
结果:大约每六七次就出一次格式错误。frontmatter 少了 created 字段,日期格式不对,wikilink 漏了方括号。在几百次操作之后,这些格式错误的卡片会污染后续的搜索和链接。
解决方案是两层设计。对比 memex 的 MCP tool:
- 低级操作
memex_write:接收完整的 frontmatter + body,agent 需要自己拼格式 - 高级操作
memex_retro:agent 只提供 slug、title、body、category,frontmatter 由代码自动生成(日期戳、source 标记),写入后还自动触发 git sync
# 低级:agent 自己拼格式(容易出错)
memex_write({ slug: "new-card", content: "---\ntitle: ...\ncreated: ...\n---\n..." })
# 高级:agent 只提供语义信息,格式由工具保证
memex_retro({ slug: "new-card", title: "New Insight", body: "...", category: "architecture" })memex_retro 内部处理所有格式细节:YAML frontmatter 生成、日期戳添加、source 自动标记为调用方(Claude Code / Cursor)、写入后自动 sync 到远端。格式是工程问题,不要交给语言模型。
第二层:Instruction Injection
Tool protocol 定义了 agent 能做什么。Instruction 定义了 agent 应该怎么做。
最直观的例子是好 instruction 和差 instruction 的区别。
差的 instruction:“尽量参考之前的 memory。” 这条指令在实际运行中等于没有——agent 不知道什么算”尽量”,不知道查什么,查多少。
好的 instruction(来自我的 CLAUDE.md):
## Memory Recall
- **Session start**: At the beginning of every session, run `memex read index`
and scan for cards relevant to the current task. Read 2-3 most relevant cards
before starting work.
- **Before debugging**: When diagnosing an issue, search memex for related patterns
before tracing code from scratch.效果差距巨大。前者导致 agent 偶尔读一下 memory,大部分时候忽略。后者让 agent 每次 session 开始都主动加载上下文,每次 debug 前先查知识库——之前每个 session 开始要花 15-20 分钟”重新理解项目”,现在 2-3 分钟进入状态。
Instruction 和 tool description 互补:tool description 嵌入在工具接口里,用到工具时生效;instruction 在 context window 里,整个 session 期间生效。一个说”这个工具怎么用好”,另一个说”在什么情况下该用这个工具”。
第三层:Workflow Orchestration(Skill)
前两层解决了”agent 有什么工具”和”agent 应该遵循什么规则”。第三层解决:多个步骤怎么串成完整的工作流。
这就是 Skill 的角色。Skill = 可复用的智能工作流。
以 memory recall skill 为例。最初我把它设计成一个单步操作——搜索关键词返回结果。效果很差,因为关键词搜索太粗糙,agent 经常搜到不相关的东西然后就停了。
迭代之后变成了多步工作流:
1. 读取当前任务描述
2. 调用 memex_recall 获取 index 或搜索结果(LLM 决定关键词)
3. 读取 top 2-3 张卡片
4. 对每张卡片,检查其 [[wikilinks]]
5. 判断是否需要沿链接继续探索(LLM 决定)
6. 如果需要,调用 memex_read 读取链接目标(最多再走 2 步)
7. 综合所有读取的卡片,开始执行任务步骤 2、5 需要 LLM 判断,其余是确定性的工具调用。这就是”CLI 是纯数据层,Skill 是智能层”的具体体现。定义一次,复用无限次。
三层模型背后的原则:Progressive Disclosure
这三层分发模型不是拍脑袋设计的。它背后有一个 UI 领域的经典原则——progressive disclosure(渐进式展示)——而这个原则对 LLM prompt 同样适用。
在 UI 设计中,progressive disclosure 的意思是:不要把所有信息一次性甩给用户,按需分层展示。对 LLM 来说道理一模一样。把所有东西塞进 system prompt——工具定义、全部 instruction、所有工作流细节——会浪费 context window 并稀释注意力。模型的注意力是有限资源,塞得越多,每条指令的执行质量越低。
三层分发模型恰好对应了 progressive disclosure 的三个层次:
- 工具能力声明(始终可见)——Tool Protocol 层。MCP tool 的 description 始终对 agent 可见,定义了能力边界。但只是声明,不是执行。
- 行为准则(全程生效)——Instruction 层。CLAUDE.md、system prompt 里的核心规则,每个 session 都在起作用。数量要克制——条目越少,每条执行质量越高。
- 执行细节(按需展开)——Workflow 层。Skill 在执行过程中按需从 memory 里拉取卡片,按需展开工作流步骤。不预加载,不冗余。
信息分层不只是架构美学,也是 prompt engineering 的核心原则。你给 agent 的 context 越精准、越按需,它的执行质量越高。这跟给人类下指令是一样的道理——好的 manager 不会把所有文档甩给新员工说”自己看”,而是按任务分阶段给上下文。
三层的设计原则
- Tool Protocol:自闭环、确定性、description 即指令
- Instruction Injection:明确、具体、可验证——不要”best effort”,要”do X then Y”
- Workflow Orchestration:智能决策与确定性操作分离,可复用
违反任何一条,agent 的行为就会变得不可预测。而不可预测是 production 环境的死敌。
1.4 实战:从 0 到 227 张卡片的 Memory 系统
理论讲完了。来看实际发生了什么。
最小可用验证:agent 真的会用 memory 吗?
第一天,memory 系统只有三个命令:memex write、memex read、memex search。
没有 tags,没有链接,没有 index。Day 1 的目标是验证核心假设:agent 是否真的会用 memory?
答案是:会的,而且非常依赖。当我在 CLAUDE.md 里加上”session 开始时读取相关 memory”的指令后,agent 的表现立刻有了质的提升。这一天创建了 12 张卡片,主要是架构决策和关键 API 的接口定义。
第一个 Scaling 痛点:链接和 Tags
到了第二天,12 张卡片已经不够用了。关键词搜索太粗糙——卡片多了就不准。
这时候 [[wikilink]] 语法和 tag 过滤登场了。链接直接写在卡片正文里——要么是我手动添加,要么是 agent 在记录时自然嵌入。反向链接通过 memex backlinks 命令计算得到。到 Day 3 结束,卡片数量到了 47。
“地图”的顿悟:Index 卡片
47 张卡片,平均每张两三个链接,网络已经有了一定复杂度。agent 需要一个”地图”。
memex read indexindex 是一张手工维护的特殊卡片——所有卡片的 slug 和简短描述的概览。agent 在 session 开始时先读 index,快速扫描,决定要深入读哪些卡片。这个模式极其有效。相当于给 agent 一张地图,让它自己规划路线,而不是瞎搜。
实际上 memex_recall 这个高级 MCP 操作就是这么实现的:先尝试读 index 卡片,如果不存在就退回到列出所有卡片。
agent 的多跳探索也不需要什么特殊的 graph traversal 命令——它通过 links → read → links 的迭代调用自己实现。这正好呼应了前面的论点:LLM 做判断,CLI 做数据操作,每一步都有上下文参与。到 Day 5 结束,卡片数量突破 100。
一个具体的 Debug 案例
Day 5,一个 agent session 在处理 webhook 模块时遇到了 MCP tool 调用超时。agent 的 debug 流程:
1. 调用 memex_recall 读取 index,扫描相关卡片
→ 发现 "mcp-tool-timeout-patterns"
2. memex_read 读取该卡片
→ 内容:已知 timeout 原因列表,正文里有 [[mcp-tool-self-containment]]
3. memex_read 读取 "mcp-tool-self-containment"
→ 内容:MCP tool 必须自闭环,不能依赖外部状态
4. agent 形成假设:timeout 可能是因为 tool 内部在等待外部状态
5. 检查代码,确认:webhook handler 的 MCP tool 内部调用了
另一个服务的状态 API,该 API 响应慢
6. 修复:将状态查询移到 tool 外部,作为参数传入
7. 调用 memex_retro 创建新卡片 "webhook-handler-timeout-fix",
正文里嵌入 [[mcp-tool-self-containment]]整个 debug 过程 8 分钟。如果没有 memory,agent 需要从零开始分析,可能需要 30-40 分钟——而且可能不会想到”自闭环”这个角度。
更重要的是步骤 7:agent 把这次 debug 的经验写回了 memory。下一次任何 session 遇到类似问题,都可以直接从这张卡片开始。
这就是 memory 系统的核心价值:知识积累是跨 session 的,错误修复是一次性的。
到 Day 7 结束,项目交付,总共 227 张卡片。所有核心操作要么是读一个文件,要么是遍历一个索引。没有全局扫描,没有 re-indexing。plain text + git,扩展性几乎没有上限。这些卡片后来成了这本书的素材库。
1.5 本章小结
本章核心:工具接口 > 模型能力。 当 agent 失败时,先修 tool,不要换 model。
三层模型(MCP / Instruction / Skill)是这个原则的系统化实现——Tool Protocol 定义能力边界,Instruction 植入决策依据,Skill 编排可复用的智能工作流。而 Zettelkasten 式的 memory 系统证明了一件反直觉的事:显式结构 + LLM 判断力,在 agent memory 场景下系统性地优于黑箱 embedding。
这些原则不是理论推导。每一条背后都有至少一个具体的项目失败。
下一章,我们从 tool 和 memory 的基础设施转向一个更核心的问题:如何约束 agent 的行为? 当 agent 有了能力(tool)和记忆(memory),下一步不是”放手让它干”,而是”设计缰绳让它不跑偏”。这就是 Harness-Native Engineering——本书的核心方法论。